主页 > imtoken冷钱包安全吗 > eth开发入门门槛相关信息
eth开发入门门槛相关信息
⑴ 011:Ethash算法| 《ETH原理与智能合约开发》笔记
等待秭归中开发区块链课程:《Eth原理与智能合约开发浅显易懂》,马良授课。 这个合集记录了我的学习笔记。
总共有8节课。 其中,前四课讲的是ETH的原理,后四课讲的是智能合约。
第4课分为三个部分:
本文是第4课:Ethash算法第一部分的学习笔记。
本课介绍以太坊最核心的挖矿算法。
在介绍Ethash算法之前,先说一些背景知识。 其实区块链技术主要解决的是一个共识问题,而共识是一个层次丰富的概念。 这里缩小范围,只讨论区块链中的共识。
什么是共识?
在区块链中,共识是指哪个节点有记账权。 网络中有多个节点,理论上都有记账权。 我们面临的第一个问题是谁来记账。 还有一个问题就是交易必须要有先后顺序,即谁先到,谁先到。 这解决了双花问题。 区块链中的共识机制就是解决这两个问题,谁记账,交易顺序。
什么是工作量证明算法
为了决定众多节点中谁来记账,有很多种方案。 其中,工作量证明需要节点计算一个哈希值,满足难度目标值者获胜。 这个过程只能通过枚举来计算。 谁计算得快,谁获胜的概率就大。 收益与节点的工作量相关,即工作量证明算法。
为什么要引入工作量证明算法?
Hash Cash 于 1997 年由 Adam Back 发表,中本聪首先将其应用在比特币中以解决共识问题。
它最初是用来解决垃圾邮件问题的。
它的主要设计思想是通过暴力搜索找到一个Block headers的组合(通过调整nonce)使得嵌套的SHA256单向哈希值输出小于一个特定值(Target)。
该算法是一个计算密集型算法。 一开始挖矿是从CPU到GPU,再到FPGA,再到ASIC,使得算力非常集中。
计算能力的集中会带来一个问题。 如果一个矿池的算力达到51%,就会有作恶的风险。 这是比特币等使用工作量证明算法的系统的一个缺点。 以太坊吸取了这个教训,做了一些改进,Ethash 算法诞生了。
Ethash算法吸取了比特币的教训,专门设计了一个不使用计算的模型。 它使用 I/O 密集型模型。 I/O慢,计算再快也没用。 因此,它对 ASIC 不是那么有效。
该算法对 GPU 友好。 一是考虑如果只支持CPU,容易被木马攻击; 另一个是当前显存很大。
轻客户端的算法不适合挖矿,容易验证; 快速开始
在算法上,主要依赖于Keccake256。
除了传统的区块头,数据源还引入了随机数数组DAG(有向无环图)(Vitalik提出)
种子值很小。 缓存值是根据种子值生成的。 缓存层初始值为16M,每一代增加128K。
缓存层下面是矿工使用的数据值。 数据层初始值为1G,每代增加8M。 整个数据层的大小是128Bytes的质数倍。
该框架主要分为两部分,一是DAG的生成,二是利用Hashimoto计算最终结果。
DAG分为三层,种子层,缓存层,数据层。 这三个级别是逐渐增加的。
种子层很小,依赖上一代的种子层。
缓存层的第一个数据根据种子层生成,后面的数据根据前面的生成。 这是一个序列化过程。 它的初始大小为16M,每代增加128K。 每个元素 64 个字节。
数据层是要使用的数据。 它的初始大小是1G,现在是2G左右,每个元素128字节。 数据层的元素依赖于缓存层的 256 个元素。
整个过程是内存密集型的。
首先将头信息和随机数结合起来进行一次Keccak运算,得到初始的单向哈希值Mix[0],128字节。 然后通过另一个函数,映射到DAG得到一个值,再和Mix[0]混合得到Mix[1],如此循环64次得到Mix[64],128字节。
接下来经过后处理过程,得到mix的最终值,为32字节。 (该值在前面两小节《009:GHOST协议》和《010:搭建测试网》中均有出现)
经过计算,得出结果。 与目标值比较,小于则挖矿成功。
难度值越大,目标值越小,越难(前面需要的0越多)。
这个过程也很难挖矿批量创建以太坊钱包,也很容易验证。
为了防止矿工,混币功能也进行了更新。
难度公式见课件截图。
根据前一个区块的难度计算下一个区块。
从公式可以看出,难度由三部分组成,首先是前一个区块的难度,然后是线性部分,最后是非线性部分。
非线性部分也称为难度炸弹。 在某个时间节点之后,难度呈指数级增长。 这种设计背后的目的是在以太坊的项目周期中,在Metropolis版本之后的下一个版本中,共识将从POW变为POW和POS混合协议。 该基金会可能意味着让挖矿变得不那么有趣。
难度曲线显示,2017年10月,难度大幅下降,奖励也从5变为3。
本节主要介绍Ethash算法。 如有不足,敬请批评指正。
⑵什么是ETH以及如何购买
ETH是以太坊的编码,以太坊是以太坊区块链上的代币。 目前很多人都在投资以太坊。 对于新手来说,可能对以太币的操作方法有些迷茫。 事实上,以太币交易只需要预测其在域王国上的价格涨跌趋势,判断正确即可获利。 虽然单笔交易最低价为5美元,交易周期短至30秒,但注意不要频繁交易或重仓。
⑶ eth钱包开发(nodejs)(一)
Tips:sendEthTransaction方法结合了eth转账和token转账,转eth的时候tokenValue赋0,转token的时候赋value为0
⑷【ETH钱包开发04】web3j转ERC-20 Token
ETH转账在上一篇文章中有讲解,本篇将讲讲ERC-20 Token转账。
【ETH钱包开发03】web3j转ETH
1.直接使用web3j的API
2.Java/Android调用合约的transfer方法
无论使用哪种方式转账,都需要先编写solidity智能合约文件创建ERC-20 Token,然后部署合约,最后通过客户端调用。
注:erc-20代币转账和eth转账的区别如下:
1.方法createTransaction用于通过erc-20 token创建交易对象
2. erc-20 token需要构建一个Function,这个Function其实对应erc-20 token合约中的那些方法。 它的第一个参数是ERC20中那些方法的名字,第二个参数是对应合约方法中的参数,第三个参数对应第二个参数,照我做的就行。 转移就是转移。 从合约的转账可以看出,第一个参数是接收地址,第二个参数是金额,所以这里对应Function就好了。
该方法不需要使用web3j封装的方法,而是直接调用solidity合约的方法。
步
1. web3j 加载已部署的合约
2.验证合约加载成功isValid
3、如何加载合约成功,然后调用合约的transfer方法
注意:
1、这里的TokenERC20是根据solidity智能合约生成对应的Java类,用于java/Android与智能合约的交互。 如果你对此不清楚,不妨看看我之前的文章。

以太坊Web3j命令行生成Java版智能合约
2、如果合约加载失败,一个可能的原因是合约对应的Java类中BINARY的值不正确。 该值是您成功部署合约后的字节码。 你最好检查比较一下。
我发送交易,你可以通过这个地址查询
⑷006:MPT和RLP | 《ETH原理与智能合约开发》笔记
等待秭归中开发区块链课程:《Eth原理与智能合约开发浅显易懂》,马良授课。 这个合集记录了我的学习笔记。
总共有8节课。 其中,前四课讲的是ETH的原理,后四课讲的是智能合约。
第二课分为三个部分:
本文是第二课第二部分的学习笔记:MPT和RLP。
MPT,Merkle Patricia Tree,一种结合了默克尔树(Merkle Tree)和帕特里夏树(Patricia Tree)的数据结构。
RLP,Recursive Length Prefix,一种编码方式。
这是以太坊区块和交易中使用的两个非常重要的数据结构。
首先分别介绍Merkle Tree和Patricia Tree。
Merkle 树和 Patricia 树 Merkle 树和 Patricia 树
Merkle树的解释:计算每笔交易的哈希值(Hash),然后对两个哈希值计算它们的哈希值。 如果有奇数,就重复最后一个。 最后得到的哈希值就是默克尔树根的值。 如图所示,交易1、1、2、3的哈希值分别为HASH0、HASH1、HASH2、HASH3。 HASH0和HASH1结合计算哈希值HASH01,HASH2和HASH3结合计算哈希值HASH23,然后HASH01和HASH23结合计算哈希值HASH0123。
使用默克尔树的好处是可以方便的判断一笔交易是否在一个区块中。
Patricia Tree,可以称为压缩前缀树。 如上图右半部分所示。 相同的前缀在同一个分支,后面的公共部分fork出来,比如test和toast,都有相同的t,est和oast在两个分支。
这种结构的好处是节省空间,因为每一层的键值可以是多个字符。
了解完Merkle Tree和Patricia Tree,我们再来看一下两者混合的产物——MPT。
这里的原理性知识单独看不太好理解,但是结合具体的例子就更容易理解了。 先上课件截图。 我将在下面的例子中解释它。
Merkle Patricia 树规范 Merkle Patricia 树规范
在MPT中,还涉及三个小的编码标准。 主要规则如图所示。让我们用两个例子来说明。
三种编码标准 三种编码标准
HEX编码示例:从ASCII码表可以查到,b的十六进制编码为62,o的十六进制编码为6F,F的十六进制表示为15。 因为这是叶子节点,所以在末尾加上0x10表示结束,也就是16。所以最后的编码就是[6 2 6 15 6 2 16]
HEX-Prefix编码示例:[6 2 6 15 6 2 16],去掉最后的0x10,[6 2 6 15 6 2]。 前面加了一个四元数,其中(倒数)第0位为区分校验信息,[6 2 6 15 6 2]为偶数,第0位为0; 第1位是用来区分节点类型的,是叶子Node,第1位是1。所以这个四元组是0010是2。”如果输入key的长度是偶数,在后面再加一个4元组0x0标志 4 元组。” 因此,最终的前缀是0x20。 本例最终结果为[32 98 111 98],即[0x20, 0x62, 0x6F, 0x62]
下面是一个综合性的例子,通过它可以很容易地理解前面的理论知识。 值得多读几篇文章并仔细休会。
初始键值对为:
其中,in的数据是key的十六进制编码。
MPT.jpgMPT.jpg
因为4组数据都有一个共同的6,这个节点的值为6,长度为1,奇数; 节点类型:扩展节点; 所以前缀是0001,也就是1。
这是一个扩展节点,它的值是一个Hashvalue,指向一个分支节点。 Hashvalue具体指分支节点RLP编码结果的哈希值。 (RLP 见下一节)
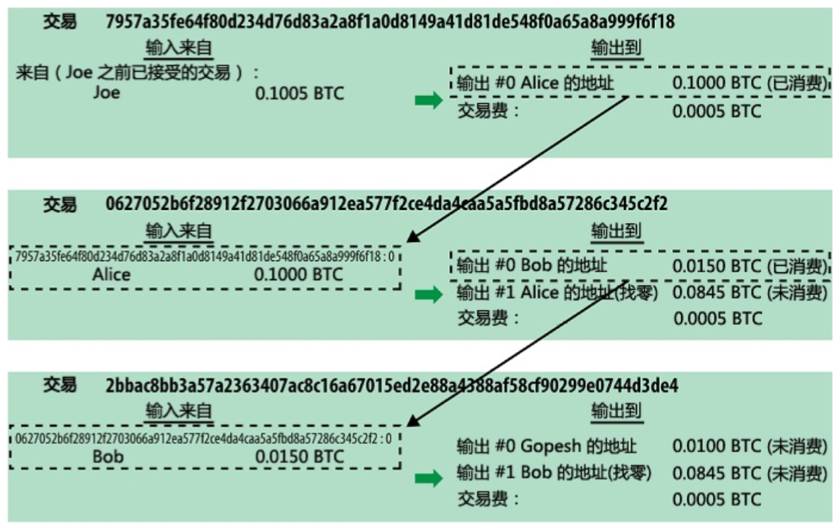
分支节点。 上面4组数据的第二位是4和8两种情况,4位存储的是下方扩展节点的哈希值,8位存储的是下方叶子节点的哈希值。
叶节点。 只有一个以68开头的。所以这个节点上的四元组是6f727365。 它是偶数位。 前缀是0x20(和上面的HEX-Prefix编码例子一样)。 此叶节点的值为“stallion”。
展开节点。 64之后,public部分是6f,这个扩展节点的key是6f,前缀是0000,也就是00。这个扩展节点的value存储了一个hashvalue,指向下一个节点,一个分支节点。
分支节点。 646f已经表达过了,这个节点的值就是646f,'verb'对应的值。
另外,646f后面跟着6,所以在这个分支节点的6位置有一个hash值,指向下一个节点。
展开节点。 646f6之后,公共部分为7,长度为1,为奇数。 所以前缀是0001。 该节点的值是指向下一个节点的哈希值。
分支节点。 646f67已经表达出来了,这个节点的值就是646f67,'puppy'对应的值。
另外,646f67后面跟着6,所以在这个分支节点的6位置有一个hash值,指向下一个节点。
叶节点。 键是 5,值是“硬币”。 长度为1,奇数,前缀为0011,即3。
整个分析过程结束。 可以结合上图和之前的理论进行更多的复习。
本节的理论性也很强,可以通过示例轻松理解。 先放课件,再根据自己的理解多举例子。 同样,学习方法是理论与实例相结合。 其中,list的例子会在下一篇上机实验部分再次列举。 RLP编码标准 RLP编码标准 多举几个例子 多举几个例子
⑵ ETH开发实践——批量发送交易
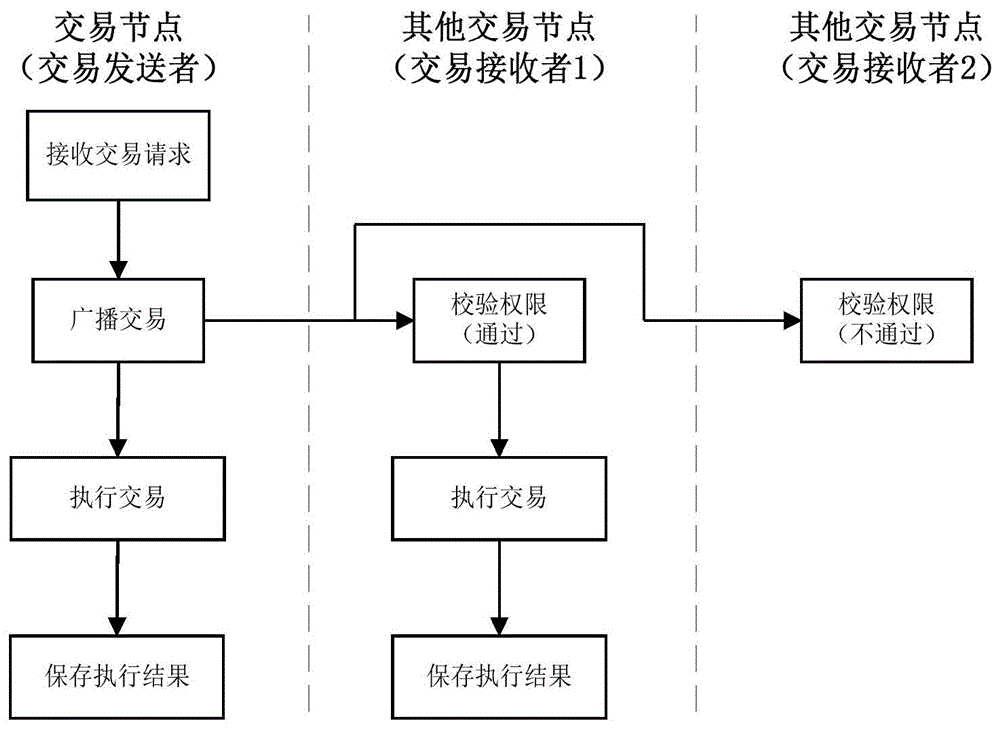
当使用同一个地址连续发送交易时,往往不可能每笔交易都立即到达。 如果当前交易还没有到来,可以通过eth.getTransactionCount()获取nonce值来设置下一笔交易,或者由节点自动从区块中查询,并会获取与上一笔交易相同的nonce值。 此时节点会报错Error: replacement transaction underpriced
当构造一个新的交易时,会在交易数据结构中产生一个nonce值。 nonce是当前区块链下发送者(from地址)发送的(成功记录到区块中的)交易总数加1。比如构造一个新的从A到B的交易,则之前的交易数A的地址为10,那么这笔交易中的nonce会被设置为11,验证通过后节点会被放入交易池(txPool),并广播给其他节点,交易等待矿工打包它进入一个新的块。
那么,如果先构造并发送一个来自地址A的nonce为11的交易,在该交易被打包进区块之前,构造另一个来自A的交易并发送给节点,是否是通过获取的过去交易的数量web3的eth.getTransactionCount(A),还是节点自己填nonce,后面的交易的nonce也是11,这时候出现问题:
在实际场景中,会有从一个地址批量发送交易的需求。 首先,这些操作也可以并行化。 我们不会等到一笔交易成功写入区块后才发起第二笔交易。 那么此时有什么? 有什么好的解决方案?我们先来看看geth节点中交易池的交易处理流程
前面说过,如果在构造交易时没有手动设置nonce值,geth节点会默认计算出发起地址之前的最大nonce数(只计算写入区块的数),然后加1它,然后将交易放入节点交易池中的待处理队列中,等待节点将其打包进块。
在构建交易时,可以手动设置nonce值。 如果当前的nonce应该设置为11,而我手动设置为13,当节点收到交易时,发现地址下的nonce并没有更改为11和12交易,nonce为的交易13会被放入交易池的queued队列中。 只有在前面的nonce完成后(找到nonce为11和12的交易并放入pending队列),才会放入pending队列进行打包。
我们将待处理队列中的交易视为可执行的,因为它们可能被矿工包含在最新的区块中。 queue队列由于缺少之前的nonce,暂时无法被矿工打包,称为不可执行交易。
那么在实际开发中,从一个地址批量发送交易时应该怎么做呢?
方案一:那么,从一个地址批量发送交易时,可以持久化一个本地nonce,在构造交易时使用本地nonce进行累加,逐条填充到后续交易中。 (需要注意的是,本地的nonce可能会出现偏差,可能需要周期性地从区块中重新获取nonce,并在本地进行更新)。 这种方式也有一定的局限性,适用于内部地址(即只有本服务会使用这个地址发送交易)。
说到这里,还有一个坑。 很多人认为通过eth.getTransactionCount(address, "pending"),第二个参数是pending,可以得到包括本地交易池pending队列在内的nonce值,但实际情况并非如此。 这里的pending只包括要放入打包块的交易。 假设写入的交易块数为20,发送nonce为21、22、23的交易,则上述方法得到的nonce可能为21(之前的21、22、23没有放入要打包的块),也可能是22(前面的21已经放入要打包的块中,但是22和23还没有放入)。
第二种方案是每次构造交易时,从geth节点的pending队列中获取最后一个可执行交易的nonce,加1,然后发送给节点。 交易池列表可以通过txpool.content或者txpool.inspect获取,在里面可以看到pending和queue的交易列表。
启动节点时,可以设置交易池中每个地址的待处理队列容量上限,队列队列容量上限,待处理队列和队列容量上限整个交易池的队列。 因此,在高并发的批量交易中,需要增加节点的交易池容量。
当然,除了扩大交易池和控制发送频率外,还需要设置合理的交易手续费。 交易写入以太坊区块的速度取决于交易费用和以太坊网络的拥塞情况。 在发送每笔交易时,设置合理的矿工费,避免交易池大量积压交易。
⑺【ETH钱包开发02】导入钱包
本文主要讲解如何通过助记词、keystore、私钥导入钱包。 导入钱包就是根据三个输入之一重新生成一个新的钱包。 导入钱包的过程其实和创建钱包的过程差不多。
根据助记词导入钱包不需要原密码,可以重置密码。 根据用户输入的助记词,先验证助记词的合规性(格式、数字等),验证无误后用用户输入的密码重新生成新的钱包。
验证助记词的合规性(格式、数字等)
导入助记词到钱包

通过私钥导入钱包与创建钱包基本相同。 因为私钥在导出的时候会转成十六进制,所以在导入私钥的时候需要把十六进制转成字节数组。
keystore就是钱包文件,其实就是钱包信息的json串。 导入密钥库需要输入密码,该密码是您上次导出密钥库时使用的密码。 将keystore字符串改成walletFile实例,然后通过Wallet.decrypt(password, walletFile)解密; 成功则可以导入,否则不能导入。
这是Web3j的API,程序经常在这里OOM!
具体原因我就不多说了,大家可以看这里
解决方案
根据源码修改解密方法,这里我使用修改后的第三方库
修改后的解密方法
导入Kestore
1、导入助记词和私钥不需要之前的密码,需要重新输入新密码; 导入密钥库需要以前的密码。 如果密码不正确,会提示地址和私钥不匹配。
2.关于备份助记词
用过imtoken的同学可以看到imtoken可以导出(备份)助记词。 我一开始也对这个很疑惑,后来才知道真正创建钱包的时候,助记词是保存在app本地的,导出只是为了读取数据。 还有一点,imtoken备份助记词后,将不再具有备份助记词的功能,也就是说助记词会在本地存储中被删除; 并且没有导入钱包时备份助记词的功能。
⑻ iOS开发ETH钱包
框架:web3swift =>
1.创建钱包
2.导入钱包
3.取得平衡
4. 转移
5.调用智能合约
注意:
1、网络切换
测试网让 web3 = Web3.InfuraRinkebyWeb3()
主网让 web3 = Web3.InfuraMainnetWeb3()
2. transfer相关,必须配置
密钥库管理器
交易选项
3、调用智能合约时,参数不正确,直接返回nil
⑼【ETH钱包开发03】web3j转ETH
上一篇文章讲解了钱包的创建、导出、导入。
【ETH钱包开发01】创建和导出钱包
【ETH钱包开发02】导入钱包

本文主要讲解以太坊转账相关的一些知识。 交易分为ETH转账和ERC-20 Token转账。 本文将首先讨论 ETH 转账。
1.解锁账户发起交易。 钱包keyStore文件保存在geth节点上批量创建以太坊钱包,用户发起交易需要解锁账户,适用于中心化交易所。
2.钱包文件离线签名发起交易。 钱包keyStore文件保存在本地,用户使用密码+keystore签名离线交易发起交易,适用于钱包等dapp。
本文主要讲第二种方法,即钱包离线签名转账的方法。
交易流程
1.通过keystore加载传输所需的Credentials
2.创建事务RawTransaction
3.使用Credentials对象签署交易
4.发起交易
请注意以下几点:
一、证件
这里,我通过获取私钥来加载Credentials
还有一种方式是通过密码+钱包文件keystore来加载Credentials
2.随机数
nonce是指发起交易的账户下的交易次数。 每个账户的nonce从0开始,处理完nonce为0的交易后,会处理nonce为1的交易,依次添加nonce为1的交易。 被处理。
nonce可以通过eth_gettransactioncount获取
3.gasPrice和gasLimit
交易费用由gasPrice和gasLimit决定,实际交易费用为gasUsed * gasPrice。您可以自定义这两个值,或者使用系统参数获取当前两个值
关于gas,可以参考我之前的文章。
以太坊(ETH)GAS详解
gasPrice 和 gasLimit 影响转账速度,如果 gas 太低,矿工会最后打包你的交易。 在应用程序中,通常会给出一个默认值,让用户选择手续费。
如果不需要自定义,还有另一种获取方式。 获取以太坊网络上最新一笔交易的gasPrice。 对于转账,gasLimit 一般设置为 21000。
Web3j 还提供了另一种简单的方式来传输以太坊。 这种方式的好处是不需要管理nonce,不需要设置gasPrice和gasLimit,会自动获取最近一笔交易的gasPrice,gasLimit为21000(转账一般设置为This值足够)。
我想这个问题是很多朋友关心的。 但是到目前为止,我还没有看到一篇博客解释这方面的内容。
之前问过一些朋友,他们说可以通过区块号,区块哈希,或者Receipt日志来判断。 但是经过一番尝试,只有BlockHash是可行的。 在web3j中,根据blocknumber和transactionReceipt会报空指针异常。
原因大概是这样的:一笔交易发起后,会返回txHash,然后我们就可以根据这个txHash查询到这笔交易的相关信息。 但是当你第一次发起一笔交易的时候,由于手续费的问题或者以太网络的拥堵,你的交易还没有被矿工打包进区块,所以一开始是不可能找到的,通常是需要几十秒甚至更长的时间才能得到结果。 我目前的解决方案是通过轮询的方式刷新BlockHash。 一开始BlockHash的值为0x00000000000,打包成功后不再为0。
这里我使用rxjava的方法进行轮询刷新,每5s刷新一次。
正常情况下,几十秒内即可获取区块信息。
区块确认数=当前区块高度-交易打包时的区块高度。
⑽ ETH开发实战——如何获取合约地址
当智能合约成功部署到ETH网络后,将获得合约地址。 那么,什么决定了合约地址呢? 合约地址由本次部署交易中合约创建者的地址(发送方地址)和nonce(发送方累计交易次数)决定。 发送者和随机数通过 RLP 编码后,使用 Keccak-256 (SHA3) 进行哈希处理。 最后截掉前12个字节,得到合约地址。
js中的例子: